how to | Cleaning and preparing a movie dataset
Hi! Welcome to my > how to < post series. This post will teach you how to identify inadequate data, and prepare it for further analysis using a movie dataset. We will go through the basic steps of data cleaning, which is the first step in data preprocessing. Quality of data is very important for the data analysis process, and you can learn more about it by reffering to the GIGO concept.
Please note this a descriptive post, and not a code-along type post. You can find the corresponding code in this repository.
The Data Science Process
In short, the Data Science process includes defining a goal — a business question or a research goal — , gathering and preprocessing data, feature engineering, data exploration, modeling, and presenting your findings.
The Data Preprocessing step includes assessing data, cleaning data, data transformation, and data reduction. Assessing and data cleaning focuses on adding, correcting, repairing, or removing data that is irrelevant or incorrect.
When it comes to data cleaning, the following are the most common problems you can encounter: missing values and duplicates, irrelevant data, mismatched or mixed data types, outliers and noisy data, and structural errors. I will go through all of them using a movie dataset.
Project Goal
The goal for this specific project was to imagine being a Data Scientist for a Top Movie Studio. Now, this Movie Studio had an unfortunate series of Box Office flops, and naturally the producers decided to question their strategy. In their search for answers, they turned to their friendly neighborhood Data Scientist, where I suggested a new approach: using data to determine what factors go into making a successful film. Luckily, we had a dataset of over 5000 films to mine for insights. My producers asked me to spend some time analyzing the data and present a report detailing my findings, along with recommendations on how to revamp the studio’s strategy.
In this post I will not be dealing with the entire Data Science process for this project, only the data cleaning phase. However, it was important to include the project’s goal, as it will direct my decision-making when preparing data.
Movie dataset
The following movie dataset was given to me as a starting point in my analysis: IMDB_5000_movie_dataset.csv. Firstly, I would like to see what types of data are there, and how many features (variables):

There are both quantitative (numerical) and qualitative (categorical) data types in the dataset, expressed as Python data types: int64 and float64 for numerical data, and object for categorical data. There are a variety of features available for our analysis such as box office information, technical specification of a movie (color, duration, content rating, aspect ratio), then some basic information like language, genre, country of origin, plot keywords, as well as information about the movie’s cast and crew, social media popularity, and user and critic reviews. Total of 26 features and 5043 entries!
Missing values
Right off the bat I see that there are missing values in almost every variable. I can identify them so quickly because I know there are total of 5043 entires, and the displayed information shows there is less than 5043 in almost every feature. Now, this can be a potential problem depending on which features contain a large amount of missing data, and how it can be handled.
Missing data can be handled in two ways: imputation or removal of data. The initial analysis of the data showed there are total of 2685 missing values, where the highest percent of missing values are in the target value gross with 17.52%, followed by budget with 9.75%. Now, this in fact creates a challenge at the very start of our data cleaning process. Both of these features are tied directly to our project’s goal. Gross is the target value, it tells me the total revenue of a particular movie, hence it is clearly an important feature in the project. It also has the highest number of missing values.
By looking at a distribution matrix of these missing values, I can confirm that gross has the highest number of missing values, but I cannot see any obvious pattern:
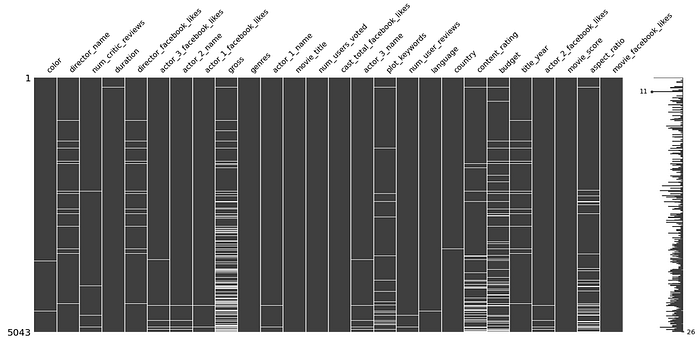
My research tells me there is no particular reason why a movie studio would not disclose their revenue, therefore I am inclined to think this information can be retrieved and added to the dataset. However, further research showed that movie studios can be reluctant in disclosing budgets for a particular movie, which can lead me to believe the missing data is hard to obtain or it is not retrievable. Best course of action would be to remove movies with missing budget values, and scrape for gross values of the remaining movies.
Because the time needed to research and input missing data exceeded this projects time frame goals, I decided to remove the missing data from the dataset.
Duplicate rows
Removing duplicates from a dataset is very important because we want to avoid misleading information, and maintain accuracy. By analyzing my dataset, I determined there are total of 247 duplicate rows, which I then proceeded to remove.
Outliers
Identifying anomalies in the dataset can be tricky just by looking at it, so it is good practice to visualize it, as we humans are more likely to catch patterns by looking at shapes rather than numbers. A pairplot does wonders for visualizing pairwise relationships. Because there are many numerical features in the dataset, I choose couple of variables I deemed might be important:
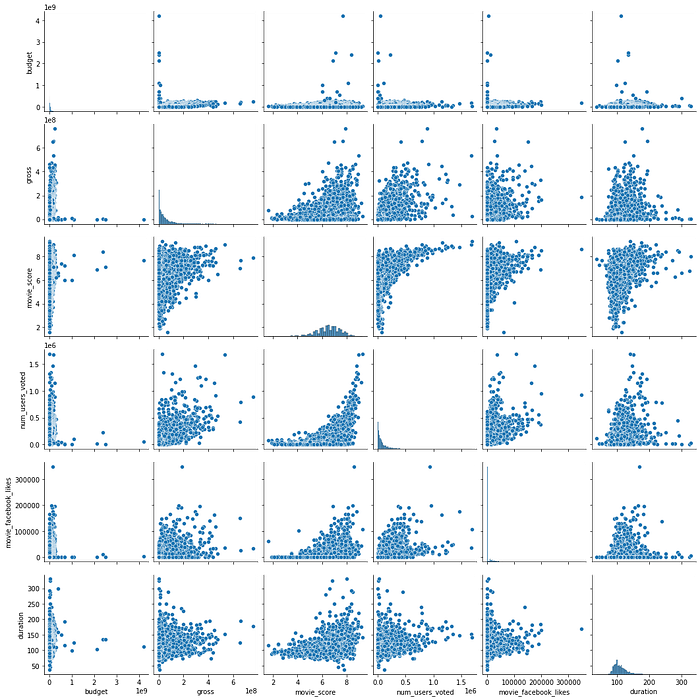
I noticed something is not right with the budget values. It appears there is a huge spike, it could mean an abnormal value. I am going to plot distributed budget values using a displot, and see what might be causing the huge spike:

There is something clearly wrong as the $4000 MM value is incredibly large for a movie budget. I found the value to be incorrectly recorded for one particular movie, and I corrected it by finding the correct budget value on the IMDB website.
Mismatched data types
My initial research regarding the one incorrect budget entry, discovered another problem, this time a mismatched data type problem. I found that specific budget values were actually in the currency of the country of origin. As such they did not represent the actual budget and gross values expressed in US dollars (USD) as I initially assumed. The highest value is a South Korean movie with a budget of 4000 million Korean wons (KRW). This is a good example of mismatched data types, which calls for either normalizing data to represent one currency, or removing it.
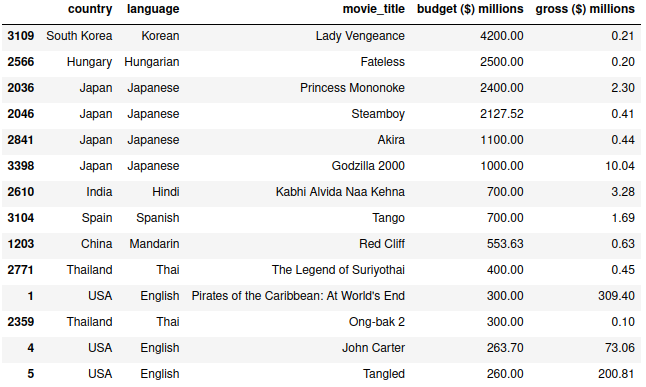
Further research showed that movies that originated in the United States share the same currency: USD. I found that to be true for movies originating from English speaking countries as well: UK, New Zealand, Australia — they all have their budget values expressed in US dollars. The best course of action would be to update the budget values to a uniform currency in USD. However, this raises a couple of questions: are budget values corrected for inflation accross all coutries in the dataset, and is there a reliable way to convert said budget values to another currency? The answers to both questions are that I cannot be sure, and it would be reasonable to ask for that information from the source, specifically if the values were corrected for inflation, and for the date of creation of the dataset in order to find the rate of exchange. However, because of the limited project time frame, I decided to remove all non-English speaking movies from the dataset.
Structural errors
Structural errors usually involve typos, inconsistent capitalization, as well as mislabeled classes. They can be found in categorical features, which we have plenty of in this dataset. However, after checking values in the categorical features, I was not able to find any structural errors.
Conclusion
The data cleaning phase of a projects is just as important as any other, as here we make sure that data is usable, consistent, and transformed to suit the project goals. Missing values, noisy data, duplicates, and structural errors are quite common, and it is very important to make your decisions goal-oriented in order to get the most suitable sample for further analysis and modeling. It takes time to prepare data as it is very likely that this is the step we will go back to many times in our project, in order to correct any errors or inconsistencies we did not catch earlier, or to transform data to a more suitable form. A good solution is to create a script, and automate the process of data cleaning, as it takes off the workload significantly.
